If you want to send formatted (HTML) emails from Domino you have a couple of options.
Starting with version 9, there’s a simple action that allows you to send HTML mail by just configuring some options. You can also use Tony McGuckin’s emailBean snippet to send an HTML mail from an XPage directly, including embedded images and/or attachments. And there’s also the SSJS snippet I wrote to send an email from any backend SSJS script.
Unfortunately, none of these could do what I wanted: send an HTML mail with the contents based on a RichText field (stored as MIME), including any embedded images. With the standard photo upload option available in the XPage embedded CKEditor it’s real easy to add embedded images. Tony’s emailBean snippet came close, but it requires a DominoDocument object as a parameter and thus only works when used directly on the XPage where you create the content. In my case, I either wanted to pick a set of documents to be send or use a scheduled agent to do that.
So I investigated how I could create a DominoDocument from a standard document object.
First stop: this snippet that uses the .wrap() function of the DominoDocument object to wrap a standard document. That worked, but didn’t add the RichText fields to the wrapped document. So I dived deeper and found the JavaDocs for the DominoDocument here. Turns out that there is a getRichTextItem() function that returns a DominoRichTextItem. That object, the DominoRichTextItem, is also used in the emailBean code. The JavaDocs for the DominoRichTextItem describe that you can use a MIMEEntity to create one. The newly created DominoRichTextItem can then be attached to the wrapped DominoDocument.
Here’s the XSnippet I just added to wrap a document, including MIME.
For this to work you need to enable the “Store contents as HTML and MIME” option of the RichText field that you’re storing the HTMl in. When you’ve done that you can use the emailBean to create and send the email:
function sendEmailFromRichText() {
DominoDocument wrappedDoc = wrapDocument(docMail, "body");
//now we can pass the wrapped document, including the MIME contents to the EmailBean
EmailBean emailBean = new EmailBean();
emailBean.setSendTo("someone@somewhere.com");
emailBean.setSubject("Here's a mail");
emailBean.setDocument(wrappedDoc);
emailBean.setFieldName("body");
emailBean.setBannerHTML("<p>Hi, " + sendTo + "</p>");
emailBean.setFooterHTML("<p>Kind regards, " + senderName + "</p>");
emailBean.setSenderEmail("i@dontexist.com");
emailBean.setSenderName("Name of the sender");
emailBean.send();
}
/*
* Wraps a lotus.domino.Document as a com.ibx.xsp.model.domino.wrapped.DominoDocument, including the RichText item
*
* @param doc document to be wrapped
* @param richTextItemName name of the rich text item containing the MIME contents that need to be wrapped too
*/
private static DominoDocument wrapDocument( final Document doc, final String richTextItemName ) throws NotesException {
DominoDocument wrappedDoc = null;
Database db = doc.getParentDatabase();
//disable MIME to RichText conversion
db.getParent().setConvertMIME(false) ;
//wrap the lotus.domino.Document as a lotus.domino.DominoDocument
//see http://public.dhe.ibm.com/software/dw/lotus/Domino-Designer/JavaDocs/DesignerAPIs/com/ibm/xsp/model/domino/wrapped/DominoDocument.html
wrappedDoc = DominoDocument.wrap(doc.getParentDatabase().getFilePath(), doc, null, null, false, null, null);
//get the RichText field containing the MIME contents as MIME
MIMEEntity rtAsMime = doc.getMIMEEntity("mailingBody");
//add the RichText field to the wrapped document
//see http://public.dhe.ibm.com/software/dw/lotus/Domino-Designer/JavaDocs/DesignerAPIs/com/ibm/xsp/model/domino/wrapped/DominoRichTextItem.html
DominoRichTextItem drti = new DominoRichTextItem(wrappedDoc, rtAsMime, richTextItemName);
wrappedDoc.setRichTextItem(richTextItemName, drti);
return wrappedDoc;
}
 So you decide to enhance the looks of your application and include Bootstrap. Bootstrap requires the btn class on all buttons for styling. Being an expert XPage developer you create a theme for your application, add the Bootstrap CSS file and add a control definition to give all buttons that btn class:
So you decide to enhance the looks of your application and include Bootstrap. Bootstrap requires the btn class on all buttons for styling. Being an expert XPage developer you create a theme for your application, add the Bootstrap CSS file and add a control definition to give all buttons that btn class:

 – wonder if there’s a hack for that without installing a proxy and keep using the standard DAS).
– wonder if there’s a hack for that without installing a proxy and keep using the standard DAS).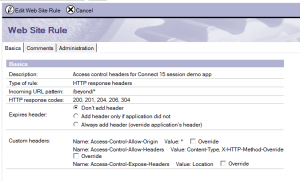
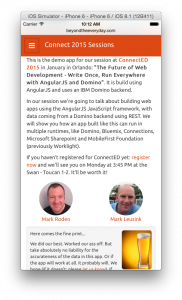 And of course there’s gonna be demos. Lots of them. But we wanted to make them useful too. So we decided to create a ‘mobile first’ Sessions demo app. Check it out at
And of course there’s gonna be demos. Lots of them. But we wanted to make them useful too. So we decided to create a ‘mobile first’ Sessions demo app. Check it out at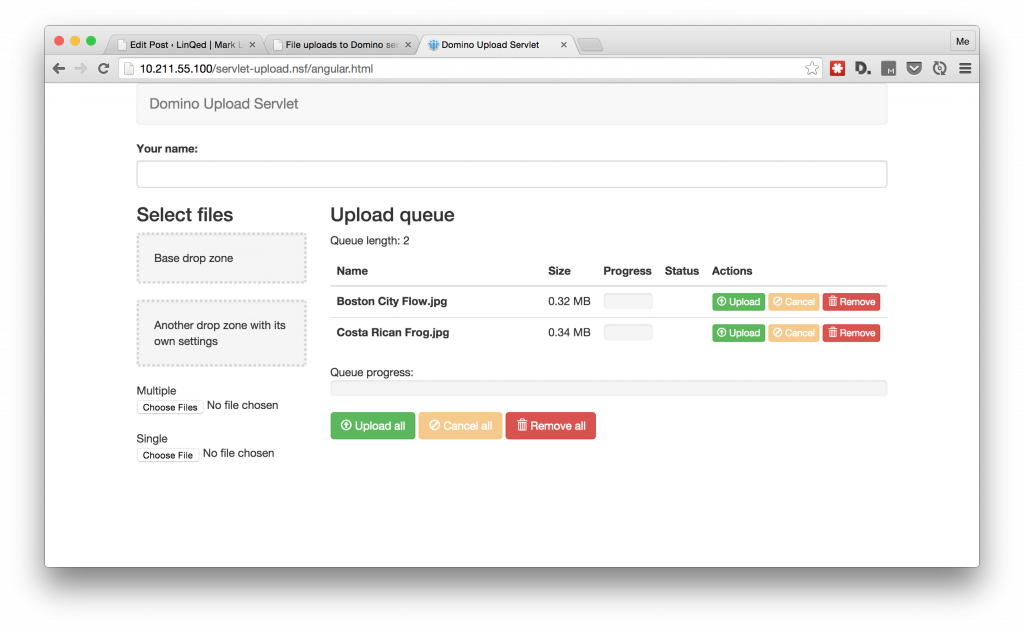


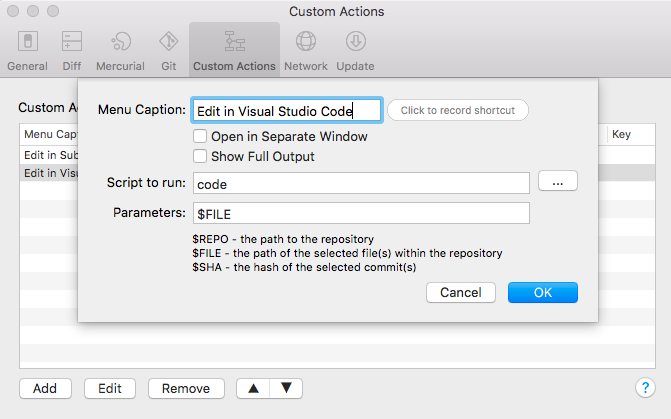
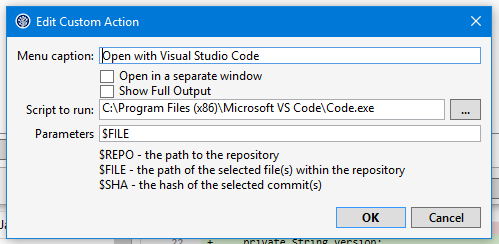
 I was doing some work with an Angular application talking to the
I was doing some work with an Angular application talking to the  So I wrote a couple of tests using the 3 APIs that traverse a view from the well known ‘Fakenames’ database. It is based on the Domino Name & Address book template and contains 40,000 documents. The tests will loop through a view called ‘People’ containing all the documents and will read a value from one of the columns.
So I wrote a couple of tests using the 3 APIs that traverse a view from the well known ‘Fakenames’ database. It is based on the Domino Name & Address book template and contains 40,000 documents. The tests will loop through a view called ‘People’ containing all the documents and will read a value from one of the columns.
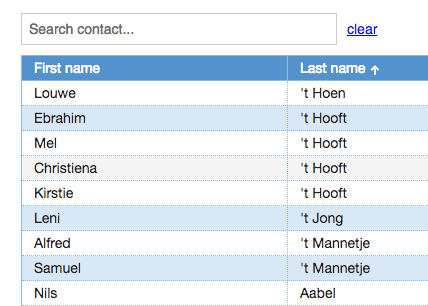
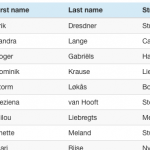 Every web application I build includes lists (or as Domino people like to call them: views) in one form of another. And then users start asking question like “But can it do sorting?” “How about a search function (on just these fields?)” “And filtering?”. With <insert-you-favorite-framework-here> that’s not too hard on short lists. I’m an Angular guy and can easily give them sorting and filtering.
Every web application I build includes lists (or as Domino people like to call them: views) in one form of another. And then users start asking question like “But can it do sorting?” “How about a search function (on just these fields?)” “And filtering?”. With <insert-you-favorite-framework-here> that’s not too hard on short lists. I’m an Angular guy and can easily give them sorting and filtering.
 With the demos from
With the demos from  Most changes need to be made in the
Most changes need to be made in the